One model to rule them all ?


2 min read

Right now there is an arms race happening in LLM world with many companies fighting to create the best model. Frankly when you look at the model landscape there is lot of diversity and lot of opinions but it is not clear if any single model is obviously better than others.
HuggingFace maintains a list of benchmarks and the performance of different models against it.
There are interesting survey papers around benchmarking as well.
Overall looks like most models in the market are remarkable similar to others and vary in performance by only a relatively smaller margin. None of the major models appear to outliers no matter what kind of performance you consider.

As above spider graph shows mores are pretty close to each other with GPT-4 allegedly might do better and in some cases significantly better.
The real story
The real story about benchmarking is that given how similar models are to each other it tells you that there is no real secret sauce to build the perfect model. Neither any of the companies seem to have any magic data that is remarkably different than others to give them competitive advantage.
This means both good and bad things. Good part here is that there will be fierce competition as anyone here could be the ultimate winner or we might have a fragmented market. This is good news for the consumers. The bad part however is that if anyone is claiming they are special they are probably lying. Also, this means there is no real path to AGI or ground breaking models that anyone has figured out. If they had figured it out their model would have outperformed everyone.
However, there might still be some narrow areas where a model might outperform others significantly. Maxim Lott’s IQ tests measurements for example show that ChatGPT O1 outperforms everyone by a great margin.
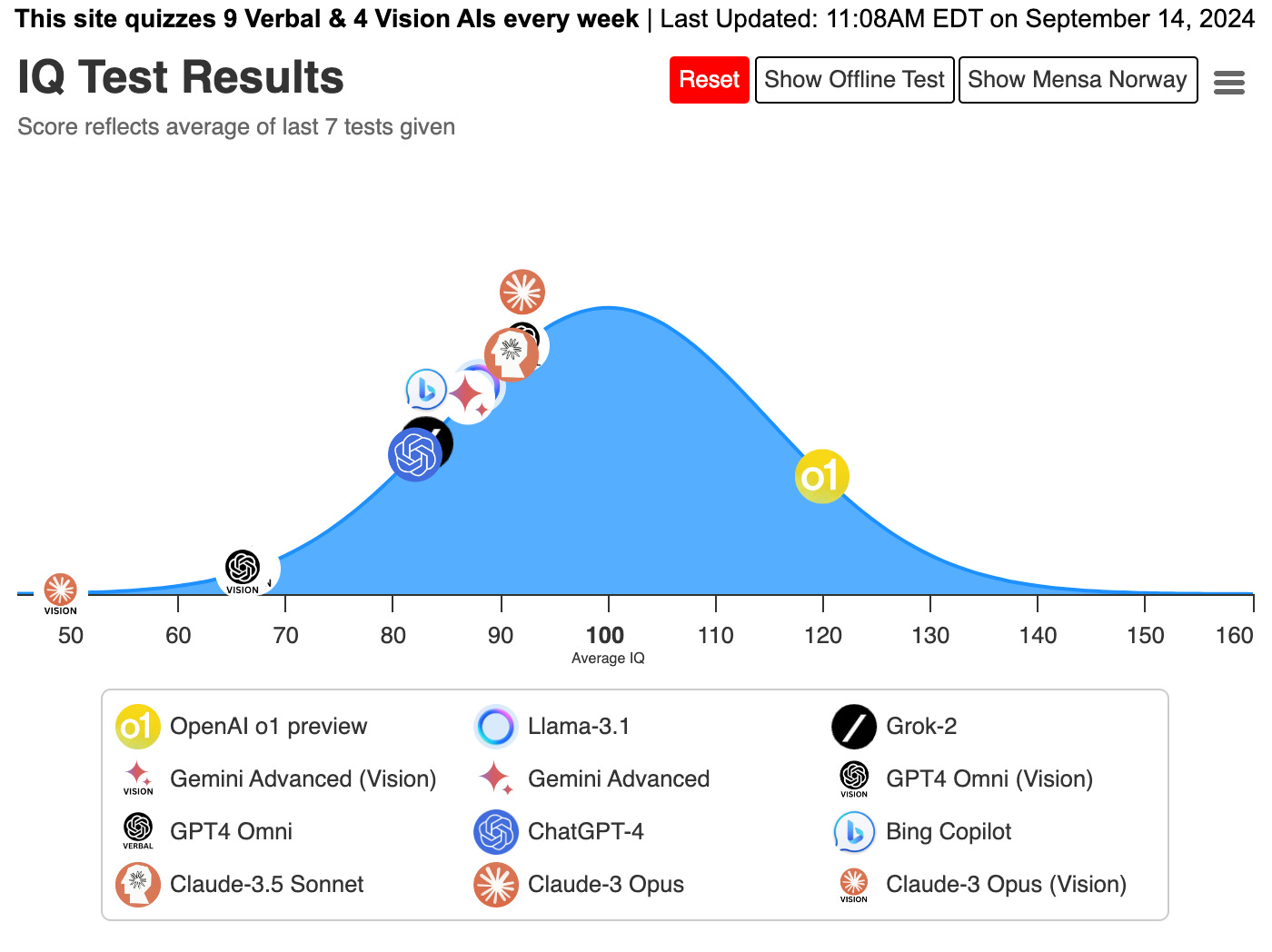
Image Source: https://www.maximumtruth.org/p/massive-breakthrough-in-ai-intelligence
The above image indicates that O1 is significantly better than everyone else. But this is a very narrow test. It does not indicate that the model is overall better. It might be due to some local impacts of specialized training and fine tuning.
We should continue to monitor benchmarks to see how these models are evolving.